Workflows Part 2 - Subworkflows and a few API Calls
An example Workflow listing Google Cloud Storage files and sending images to the Vision API.


Welcome
Recap 🔍
In the previous post I introduced Workflows on Google Cloud, the benefits of using it, and how it compares to other services. I also provided code samples of performing individual actions and how to deploy and run a Workflow.
This post dives deeper into Workflows by taking some of those concepts to create a Workflow with a few steps, calling two Google Cloud services and Subworkflows. The code is available on Github so you can try this Workflow yourself.
Workflow Example 👩🏫
I created a workflow that uses some of the concepts mentioned in the previous post. This workflow takes all images in a GCS bucket, sends them to the Vision ML API to annotate objects in each image, and writes results to Datastore (i.e. Firestore in Datastore mode). A simplified workflow can be seen below.
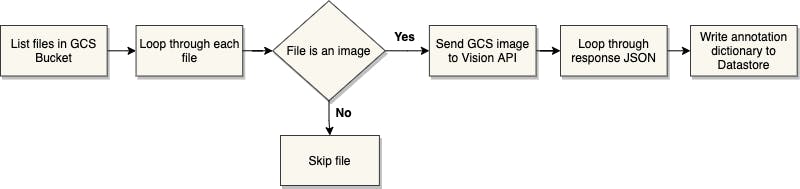
Main and Subworkflows 💨
I split the Workflow into three parts - the main workflow and two Subworkflows. The main workflow calls the storage API to list all objects in a bucket and loops through each image and labels objects by calling the Vision API. The response JSON will contain 5 annotations with a score, and each annotation is added as a single entry to Datastore. So the first Subworkflow is for calling the Vision API and the second Subworkflow is for writing entities in Datastore.
Main 🎬
The main workflow accepts a JSON containing a GCS bucket to list files. If it isn't provided, it will be assigned a default value. We also initialise a few variables required for calling the APIs.
main:
params: [args]
steps:
- initVariables:
assign:
- project: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- zone: "europe-west2"
- prefix: "image_classification"
- missingParamsCheck:
switch:
- condition: ${not("bucket" in args)}
next: bucketMissing
next: getBucketItems
- bucketMissing:
assign:
- bucket: "my-gcs-bucket"
Next we call the storage API to get information on files, specifically their name and file type. This step is wrapped in a try and except block to handle errors. I also included a logging step to send logs to GCP that can be viewed in the Logs tab in Workflows.
- getBucketItems:
try:
call: http.get
args:
url: ${"https://storage.googleapis.com/storage/v1/b/"+bucket+"/o"}
auth:
type: OAuth2
query:
prefix: ${prefix}
fields: items/name, items/bucket, items/contentType, items/timeCreated
result: bucketFilesInfo
except:
as: exception_dict
steps:
- handleGCSBucketError:
switch:
- condition: ${exception_dict.code == 404}
raise: "Bucket not found"
- condition: ${exception_dict.code == 403}
raise: "Error authenticating to GCP"
- unhandledException:
raise: ${exception_dict}
- logGetBucketItems:
call: sys.log
args:
text: ${"Read metadata on buckets stored in variable = " + json.encode_to_string(bucketFilesInfo)}
severity: INFO
Note: This method of calling GCS is fine, but Workflows has many connectors available for interacting with GCP that is simpler to use. For instance I could have used the following code to list all files in a GCS Bucket. I kept the original code to compare the differences in syntax.
- readBucketAlternative:
call: googleapis.storage.v1.objects.list
args:
bucket: ${bucket}
prefix: ${prefix}
userProject: ${userProject}
result: bucketFilesInfo
To read more on the list function for GCS buckets or other connectors go here.
The last part of the main workflow has steps for initiating a loop that will call the first Subworkflow for every image encountered in the GCS bucket. This consists of setting an iterator variable, i, and using switch and conditional statements to determine next step to be executed.
Conditions
- If the index + 1 equals total number of files in the bucket then go to the last step
- If the file type is not a JPEG or PNG then go to skipNonImageType
- Otherwise go to the step callVisionDatastoreSubworkflow, which starts the Subworkflow and pass in necessary parameters
- setupSubworkflowLoop:
assign:
- i: 0
- result: ""
- subworkflowCondition:
switch:
- condition: ${len(bucketFilesInfo.body.items) == int(i+1)} # the next condition throws an error on the last index
next: outputResults
- condition: ${bucketFilesInfo.body.items[int(i)].contentType != "image/jpeg" AND bucketFilesInfo.body.items[int(i)].contentType != "image/png"}
next: skipNonImageType
next: callVisionDatastoreSubworkflow
- skipNonImageType:
assign:
- i: ${i+1}
next: subworkflowCondition
- callVisionDatastoreSubworkflow:
call: sendVisionAPIRequest
args:
project: ${project}
bucket: ${bucket}
bucketFilesInfo: ${bucketFilesInfo}
index: ${i}
result: i
next: logFirstLoopIteration
- outputResults:
return: ${result}
Subworkflow 1 - Vision API 👁️
When the main workflow calls the first Subworkflow, sendVisionAPIRequest, it behaves like a separate workflow that has its own variables. The first few steps creates the request JSON and structures it in the same way as outlined here. Due to its nested structure that consists of both dictionaries and lists, I separated the steps for building the final request JSON as it was easier to debug. The main request parameters required are the imageUri, and type as the Vision API can perform many different operations; I'm only interested in label detection.
sendVisionAPIRequest:
params: [project, bucket, bucketFilesInfo, index]
steps:
- createVisionAPIFeaturesDict:
assign:
- visionFeatures:
source:
imageUri: ${"gs://" + bucket + "/" + bucketFilesInfo.body.items[index].name}
- createImageDict:
assign:
- features: [
type: "LABEL_DETECTION"
maxResults: 5]
- createVisionAPIDict:
assign:
- requestsDict:
requests: [
features: ${features}
image: ${visionFeatures}]
- logURLDict:
call: sys.log
args:
text: ${"The request json for the vision API = " + json.encode_to_string(requestsDict)}
severity: INFO
The second half of this Subworkflow calls the Vision API and initiates another loop that will call the second Subworkflow, datastoreRequest, which writes each label as its own entity in Datastore. Again, this is structured in a similar way to the previous loop by using a combination of conditions and jumps to control flow of execution based on variables.
- classifyImages:
try:
call: http.post
args:
url: ${"https://vision.googleapis.com/v1/images:annotate"}
auth:
type: OAuth2
body: ${requestsDict}
result: imageClassified
except:
as: visionError
steps:
- handleVisionError:
raise: ${visionError}
- setupDatastoreWriteLoop:
assign:
- iter: 0
- result: ""
- datastoreCheckCondition:
switch:
- condition: ${len(imageClassified.body.responses[0].labelAnnotations) > int(iter)}
next: callDatastoreSubworkflow
next: outputResults
- callDatastoreSubworkflow:
call: datastoreRequest
args:
project: ${project}
visionDict: ${visionFeatures}
visionResult: ${imageClassified}
iter: ${iter}
result: ${result}
result: iter
next: datastoreCheckCondition
- outputResults:
return: ${index+1}
Subworkflow 2 - Writing to Datastore ✍️
For this Subworkflow I am taking the results from the Vision API request and writing each label annotation as it's own entity in Datastore with a few properties attached to it including the image URL, a timestamp and an array of the response.
As mentioned earlier it's much easier to interact with Google Cloud by using their connectors. Unfortunately for me I have Firestore in Datastore mode, which is not supported, so instead of creating a new project I powered through to make it work with my current environment. Similar to the Vision API request it was a bit tricky getting the format correct to work with the API, but the steps I've written to make it work is as follows.
datastoreRequest:
params: [project, visionDict, visionResult, iter, result]
steps:
- startDatastoreRequest:
try:
call: http.post
args:
url: ${"https://datastore.googleapis.com/v1/projects/"+project+":beginTransaction"}
auth:
type: OAuth2
result: datastoreTransactionID
except:
as: firstDatastoreError
steps:
- raiseTransactionError:
raise: ${firstDatastoreError.body}
- getCurrentTime:
call: http.get
args:
url: http://worldclockapi.com/api/json/utc/now
result: currentTime
- writeToDatastore:
try:
call: http.post
args:
url: ${"https://datastore.googleapis.com/v1/projects/"+project+":commit"}
auth:
type: OAuth2
body:
mutations:
insert:
key:
path:
kind: "image_annotation"
partitionId:
projectId: ${project}
namespaceId: "workflows-gcs"
properties:
gcs_link:
stringValue: ${visionDict.source.imageUri}
current_time:
stringValue: ${currentTime.body.currentDateTime}
annotations:
stringValue: ${visionResult.body.responses[0].labelAnnotations[iter].description}
annotation_array:
arrayValue:
values:
entityValue:
properties:
description:
stringValue: ${visionResult.body.responses[0].labelAnnotations[iter].description}
score:
doubleValue: ${visionResult.body.responses[0].labelAnnotations[iter].score}
topicality:
doubleValue: ${visionResult.body.responses[0].labelAnnotations[iter].topicality}
transaction: ${datastoreTransactionID.body.transaction}
result: datastoreResult
except:
as: datastoreError
steps:
- raiseDatastoreError:
raise: ${datastoreError.body}
- returnResults:
return: ${iter+1}
How does it look? 🖼️

So if my bucket has an image like the one above then the Vision API will identify up to five objects in the image. After writing the results to Datastore it looks like this.
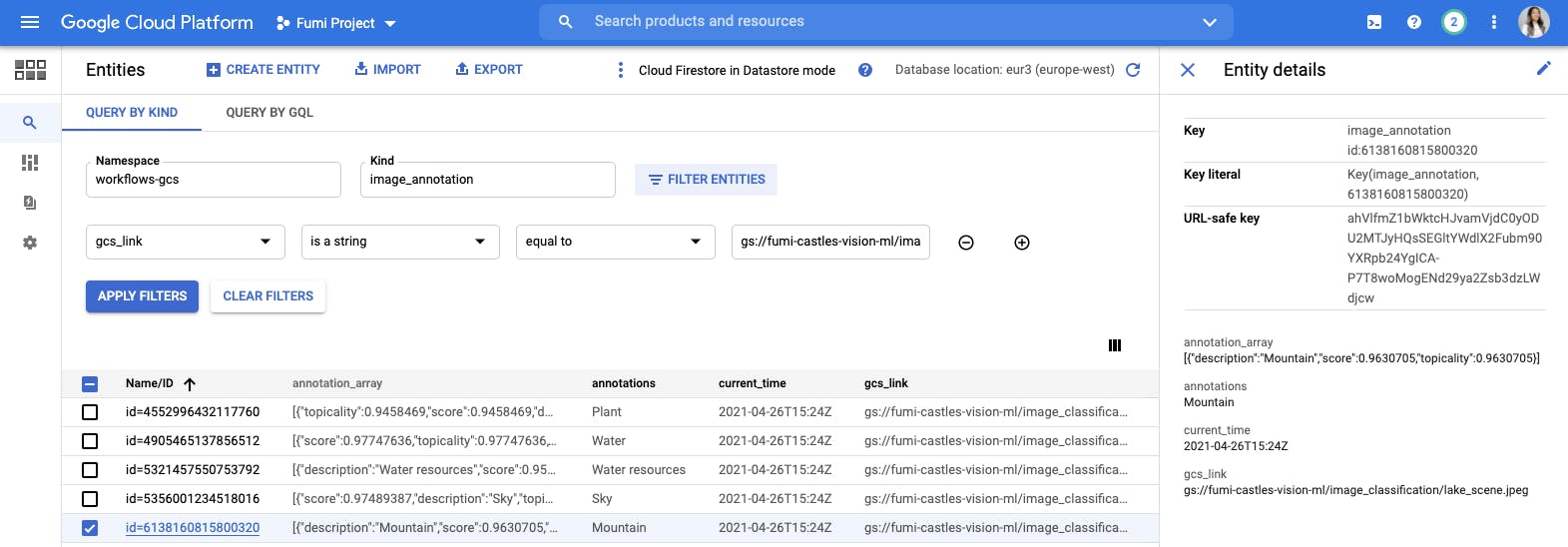
It will do this for all images in the bucket and you'll see a succeeded state on the Workflow if things went well. If not, you will see a failed state where you can investigate the error.
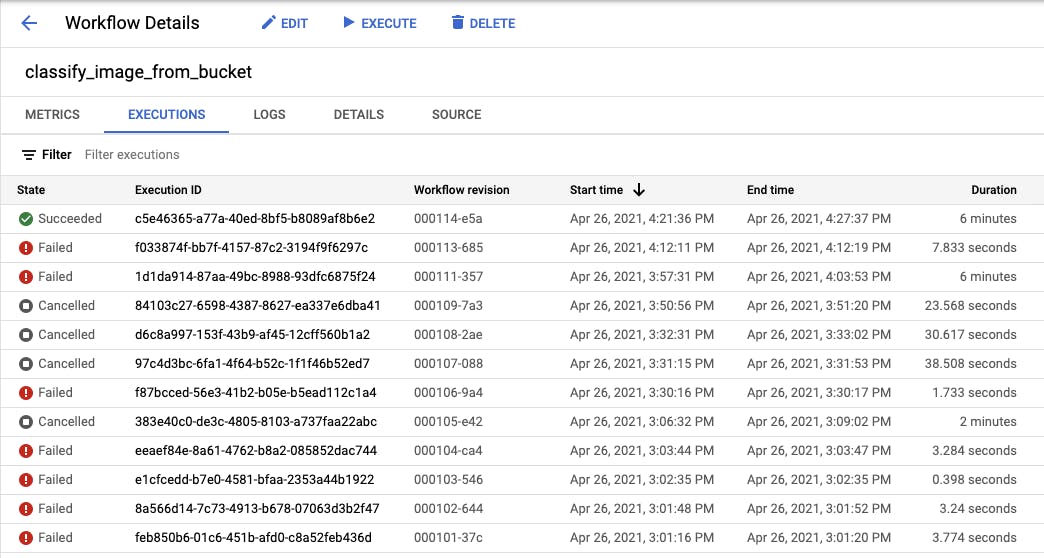
Sometimes the cause of error isn't obvious so I created a few logging steps in my workflow to see the structure of my nested dictionaries and validated they match the expected JSON for http calls.

Just in case you were wondering why a few Workflow executions were cancelled - they were stuck in an infinite loop and wrote over 100s of entries to Datastore. Ensure your loops are written correctly so they don't do that too 😊
To see the full YAML code for this process please see my github here.
Lessons Learned Part 2 💡
- It seems that steps can only return a single parameter
- It's much easier to call Google Cloud services if there is already a connector to the API. See the list here
- Subworkflows are like functions and you need to pass in arguments and use return values
- You can define dictionaries in a YAML using JSON notation (e.g. with { and }), but if you use expressions then you'll have to use spaces and newlines to create nested structures
- API documentation is your friend
Thank you for reading 👋
Thank you for reading and I hope this example clarifies how to write certain steps, what pitfalls to avoid and perhaps the code can be modified for your use case.
Please leave a comment and let me know what you think!