Vertex AI - An Overview
A high-level overview of the Vertex AI Platform on GCP.


Introduction
I'm sure you have heard the fuss about Vertex AI - an end-to-end machine learning platform on Google Cloud that went GA last year. However, at first glance, it can be incredibly intimidating and confusing as there are many components. This guide's purpose is to provide a high-level view of the entire offering in an easy-to-consume manner. In the future, I will dive deeper into specific areas, including tutorials for getting started.
Note: I am not a data scientist and will not delve into technical terms or explain data science concepts in this post.
wtf is Vertex AI? 🤔
Vertex AI is an AI/ML platform with services that support each stage of the machine learning lifecycle, from exploring data to training models and productionising them for services. If you used CAIP (Cloud AI Platform) before, this is the rebranded version with additional products such as NAS (Neural Architecture Search).
As you can tell from the diagram, this is a behemoth platform, and it can be bewildering without seeing a categorisation of products.
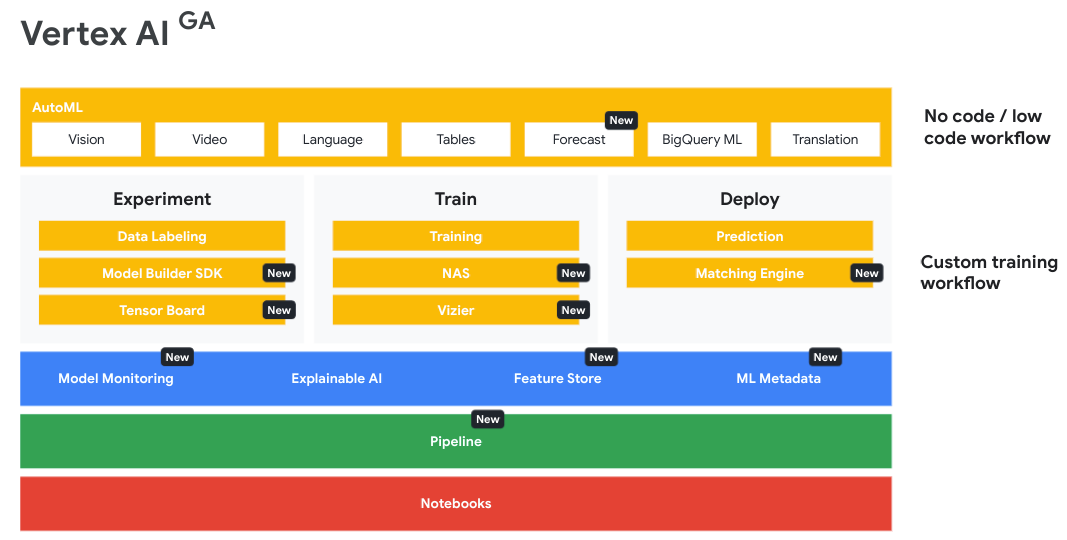
Vertex AI Products 🤖
1. No Code / Low Code 🗃️
One of my favourite things about working at Google is the view that machine learning shouldn't be limited to organisations with advanced data science skills. They want to democratise ML (as well as analytics and other technical domains). Thus they have a variety of out-of-the-box APIs and AutoML models available to use.
These are categorised by data types or use cases:
- Vision AI - use advanced ML models to detect emotions, and objects, understand text and more.
- Video AI - obtain rich metadata at video, shot or frame level
- Translation AI - make content multilingual fast into 100+ languages
- Speech-to-Text or Text-to-Speech - rapidly converting between audio and text in real-time.
- Dialogflow - create advanced conversational experiences using powerful natural language processing capabilities
- Cloud Natural Language - classify, extract and detect sentiment by analysing unstructured text
- Timeseries - Easily detect anomalies and other analyses from significant amounts of time series data.
AutoML creates custom ML models on tabular, image, video or text data. AutoML is extremely powerful and seamless to use. Provide your labelled dataset, set a few parameters (such as training hours), and it runs on the platform for you. The result is an efficient model because it utilises Transfer Learning, which takes a pre-trained model as the starting point for a new model. For example, a convolutional neural network may be used to train on an image dataset. The initial layers remain the same, but succeeding layers are modified to work with the new image dataset for a particular use case.
On the topic of Vision use cases, there's also an excellent service on Google Cloud called Explainable AI that works on tabular and image data. It helps you understand a model's output for classification and regression tasks by showing how much a feature contributed to its predicted result. This service is helpful as machine learning models appear to be black boxes, but this product pinpoints which features influenced the outcome.

In the above image, the green layer shows the pixels that contributed the most to the final prediction.
2. End-to-End Data Science Workflows with Workbench 📔
Most technical users in the data science and analytics community use Python and love experimenting with data using Jupyter notebooks. However, users usually don't want to manage the infrastructure and configure things to work - they want to focus on analysing data and creating models.
Workbench provides a Jupyterlab environment with common data science frameworks such as TensorFlow. Google manages the environment, so infrastructure provisioning isn't needed, but you can select machine types for your use case. Integrating with other GCP products such as BigQuery or Google Cloud Storage (GCS) is easy. You can also use custom containers, schedule your notebook to run at a specific time, and enforce idle shutdown to reduce costs.
If a user needs more control over the environment, there's the option to deploy User-Managed Notebooks. These are usually for users who need a more custom environment or may have specific networking or security needs. In many cases, the Managed Notebook option should suffice. A granular comparison between the two can be found here.
3. Data 📊
Datasets 💽
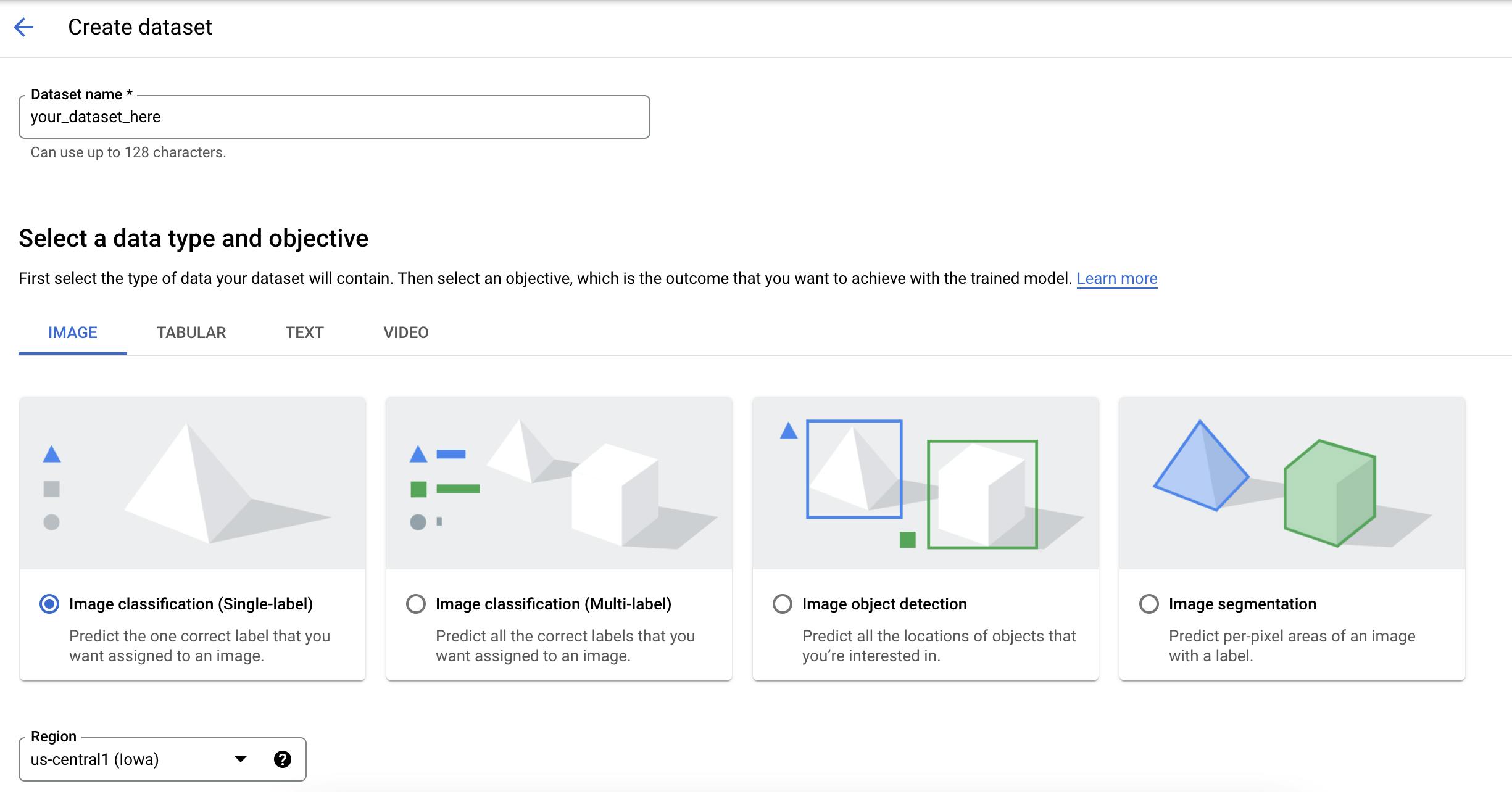
It's possible to ingest data directly from your training job, but the recommended approach is to utilise Managed datasets on Vertex AI. This feature allows you to manage your data from a single view. It makes it easy to control data and perform other data preparation tasks such as labelling, tracking lineage, viewing data statistics and splitting data into train/test/validation sets.
Currently, you can import either tabular, image, video or text datasets from Google Cloud Storage (or BigQuery for Tabular data). Datasets are linked to a region, so ensure you pick the one appropriate for your use case.
Data labelling 🏷️
Have a lot of data that requires labelling, but you can't do the task yourself? That's where the Data Labeling Service comes in handy. Provide GCP with your dataset, a list of all possible labels and instructions for the human labellers to follow. This service is helpful if you don't want to do the task yourself. However, it can take up to 63 days, and you should check out the documentation here before submitting a job.
Feature Store ⭐
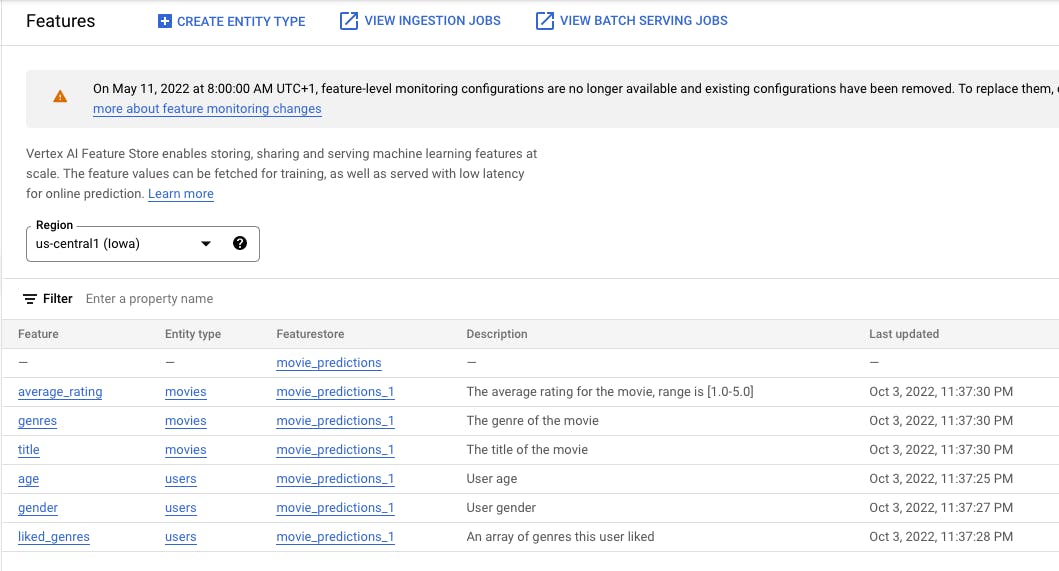
With Vertex AI Feature Store, you can create a featurestore with ready-to-use features for machine learning tasks. It's essentially a catalogue of features where people can search and retrieve values for their models. Having a central repository of features eliminates the need to maintain and organise them in storage like GCS, and sharing features with others in an organisation is simple. It also ensures consistency and reduces duplicate efforts.
Like many other Google Cloud services, it is managed and can support online feature serving (i.e. low-latency), so your online predictions are completed quickly. This provides a high-performance platform, ensuring users can focus on their data science tasks instead of operational ones. It mitigates training-serving skew by ensuring feature values are the same when training a test and production-ready model. You can see drift by viewing changes to feature data distribution with feature monitoring functionalities.
4. Creating Models 👩💻
Experiments 🧪

When creating a model, a user must analyse the data and test different models and parameters to find the one that performs best. Google makes this process easier with Experiments. You can compare model metrics, view a model's lineage (steps and artefacts), and track and compare pipeline runs. After running various experiments, pick the model that performed best for your use case.
5. Training Models 🏋️♀️
Training 🚆
One of the biggest tasks for creating a model is the training job. In Vertex AI Training you will find all previous training jobs for AutoML and custom models. AutoML will automatically initiate a training job for you, so no work is required. However, if you deploy custom models, you will utilise the Training pane more.
Similarly to other GCP products, provisioning infrastructure is automatic and serverless.
Things to know regarding training custom models
- You can either use a pre-built container or provide your own. Use a pre-built container if the images contain the required framework and package versions.
- Follow the custom training guidelines, including correct IAM permissions are granted and using Vertex managed datasets where possible.
- The virtual machines that run the training job cannot be accessed after the job is finished. Therefore the resulting model must be exported to GCS.
The bottom line is there are ways of simplifying the custom model training experience, but at the same time, if you have particular requirements, then the platform can support them.
NAS 🧠
"In 2017, the Google Brain team recognised we need a better way to scale AI modelling, so they developed Neural Architecture Search technology to create an AI that generates other neural networks, trained to optimise their performance in a specific task the user provides" Source
Neural Architecture Search (NAS) is the process of iteratively creating neural network architectures with an automated process (i.e. machine learning) that optimises on specific metrics such as latency or memory to identify the best architecture and settings. This new feature (not yet GA!) can help machine learning teams develop high-performing models while significantly reducing development time. Keep an eye out for this feature, as it will be generally available soon!
Vizier ⬛
AI Platform Vizier is a black-box optimisation service that helps you tune hyperparameters in complex machine learning (ML) models. When ML models have many different hyperparameters, it can be difficult and time-consuming to tune them manually. AI Platform Vizier optimises your model's output by tuning the hyperparameters for you.
This optimisation service is best for a system that doesn't have a known objective function to evaluate or is too expensive to evaluate with the objective function because it's too complicated. If you don't mind not fully understanding the system (hence black-box) but need to optimise the hyperparameters, then this service will be helpful.
6. Deploy 🚀
Prediction 🔮
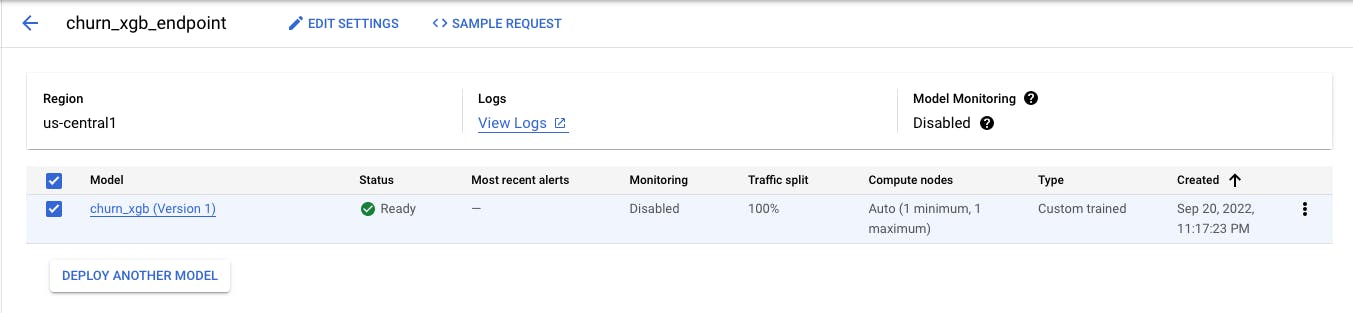
When you create a model, you'll want to deploy it so it can run predictions. There are two types of predictions:
- Online: A prediction that must return immediately
- Batch: Asynchronous requests where predictions return slower than Online.
Vertex AI makes it simple to deploy models as an endpoint that can be used in your applications. For batch predictions, provide a data file for a particular model, and it'll respond with the results as soon as possible. Even better, the platform will automatically scale based on traffic.
Matching Engine ✔️
If you have a use case that requires grouping semantically similar items, such as a recommendation engine or text classification, then the Matching Engine service might be for you. I say might, because a recommendation engine use case is probably better suited to GCP's Recommendation AI service. Regardless, the matching engine helps users develop semantic matching systems using vector calculations (specifically ANN-Vector Similarity Search) to classify examples into similar or dissimilar. Examples close to each other are similar and dissimilar if far apart. It's also fully managed, so it's fast and scales for you.
7. MLOps 🎛
In my previous life as a data engineer, I learned the importance of defining robust data pipelines for creating data assets. They ensure steps are adequately defined, followed, automated, and outputs are validated against metrics tests. Furthermore, monitoring and governance should be embedded in the system for running pipelines.
Generally speaking, the machine learning process looks like this:
Obtain data -> Prepare data -> Train the model -> Evaluate the model -> Validate the model -> Deploy the model
These steps will occur on an iterative basis, so the deployed model will be a new, more efficient version than the last.
Pipelines 🚰
The new pipelines service is simpler because it's fully managed and serverless so that users can focus on pipeline development tasks. Before Vertex AI Pipelines, ML Engineers had two options -> Kubeflow Pipelines and AI Platform Pipelines (Hosted). Let's compare the two options to see precisely why Vertex AI Pipelines is better.
Kubeflow 🌊
The open source project was released in April 2018, a free ML framework for creating ML workflows and orchestrating the processes that prepare, create and update models. Naturally, Google tries to support open-source frameworks where possible (e.g. Dataproc for Hadoop/Spark, Data Fusion for CDAP, Cloud SQL for MySQL and Postgres, etc.), and Kubeflow is very popular. Previously, the issue with running Kubeflow pipelines on GCP is that you have to manage the Kubernetes (GKE) cluster yourself - this includes adjusting resources for larger workloads, software updates, and so on.
Hosted Pipelines 🖥
The next phase of Kubeflow on GCP was the AI Platform Pipelines, which somewhat simplifies cluster management by creating a GKE cluster and deploying Kubeflow pipelines for you. However, this doesn't give the same experience as many other GCP services that are managed or serverless.
Vertex Pipelines 🔥
Fortunately for you, GCP has released a new pipelines service that allows you to run Kubeflow and Tensorflow Extended pipelines in a serverless environment.
Additionally, it comes with a few features that make MLOps tasks easier:
- All pipelines automatically track metadata
- View lineage for artifacts produced in each stage (or specifically component) in the pipeline
- You can use various GCP security features, including IAM, VPC Service Controls (VPC-SC), and Customer Managed Encryption Keys (CMEK)
- Did I mention it's serverless, fully managed, you can run as many pipelines as you want, and you only pay for what you use? Well, now you know.
Model Monitoring 👁
ML Metadata 🕸️
As I mentioned above, there's automatic metadata tracking for Pipelines. All pipeline run metadata is captured as a graph, where each node represents an execution and artifact - each node contains metadata. Additionally, artifact lineage is included to understand factors contributing to an artifact's creation. This can include data for a model, code used to train a model, etc. Who doesn't like having more functionality with less work?
Model Registry 🗄️
Need to store, organise ML models and keep track of their versions? The Vertex AI Model Registry will do precisely that. Any model you create in Vertex (AutoML included) can be managed in the registry. It helps you manage your models, easily view model versions, and deploy new versions to an endpoint. It's the ML model version of the Artifact Registry.
Conclusion 👋
This post is a quick round-up of all available services on the Vertex AI platform. This does not cover AI/ML solutions or features on other products (e.g. BQML on BigQuery), but I hope this helps demystify the behemoth platform on GCP. I'll dive deeper into certain services with example code snippets in the future.
I would love to hear from you and any comments you have - Thanks for reading!