

Introduction to Google Cloud's Spanner
A brief overview of Spanner's architecture on GCP.


Table of contents
Introduction 👋
Everything in technology has some reliance on data whether it's analyzing trends to develop data-driven strategies for optimising profit margins, or to store transactions for a business' operations, there is a dependency on data and thus a requirement for a database.
This article introduces Spanner which is a powerful relational database on Google Cloud. I will explain why it's powerful, and how it was architected to achieve high scale and excellent performance.
Theory 📚
Before explaining Spanner and its concepts I want to start with some theory.
How should someone pick a database? Well, that depends on the requirements, but first, let's review some concepts.
Generally speaking, there are two types of databases - SQL and NoSQL.
SQL 👩❤️👨

Structured Query Language (SQL) is the programming language commonly used to interact with Relational Database Management Systems (RDBMS). Data is stored in Tables with rows and columns. It is called a relational database because tables are linked based on their relationships. For example, if there's a database on university courses, professors and students, then the course table will be linked to both the professor table (who is teaching it) and the students' table (who attends it).
attended by students <- courses -> taught by professors
Every table has a Primary Key which is a unique identifier for the record. If a table is linked to another, then it should have a Foreign Key which uses the unique identifier to link to the table it has a relationship with.
Relational Databases have been around since the 70s and common ones include MySQL, PostgreSQL, Microsoft SQL Server, Oracle.
Other than the ability to store data, what other benefits does a relational database offer?
- ACID Compliance - ensures atomicity, consistency, isolation, and durability. Data is reliable, and updates to the data don't fail regardless of errors, failures or other issues.
- Vertical Scaling - if greater performance is needed, the server needs to migrate to a resource with more CPU, RAM or SSD capability.
- Data Normalization - through the process of Normalization, the data is designed to reduce data redundancy and inconsistent dependencies. This reduces disk space and ensures tables are designed to hold relevant data.
Relational databases are beneficial as they ensure data consistency and reliability.
NoSQL 🔑
Late to the data party but incredibly important in today's data landscape are NoSQL databases. This umbrella term includes databases that don't follow the relational model.
A few examples include:
- Key-Value Store: stores data using key-value pairs. Common databases include Redis and Memcached.
- Document: extends the key-value model by storing data as documents containing various key-value pairs of data. One of the most popular databases is MongoDB.
- Wide column: on the surface, they look like relational databases, showing data in tables, rows and columns. However, there are no relational rules, and there's flexibility around column formats. GCP Bigtable is a wide-column database.
- Graph: a database that uses graph structures with nodes and edges. Designed for querying complex, interrelated objects. One of the most popular in this space is Neo4J.
Why Bother with NoSQL? ❓
SQL databases are great, but they don't work in every scenario. Why would someone consider a NoSQL database over a relational one?
- Flexible schemas - if you have a data model that changes frequently, then it's hard to make those changes to schemas in a relational database. NoSQL databases offer more flexibility, and it's useful for routinely changing data
- Horizontal scaling - as data in NoSQL databases don't follow strict relational rules, it's easier to shard data across machines in a distributed manner. Whereas horizontally scaling a relational database is much more complicated. There's a lot of maintenance effort required to store data across multiple machines, and then join it all together when queried. Also, it's challenging to ensure ACID guarantees.
However, there are drawbacks. Most NoSQL databases don't offer ACID transactions, so you may not always have consistent data. Additionally, you might not achieve all of your use cases with a single NoSQL database. For example, a graph database is excellent for traversing and understanding complex relationships, but it might be inefficient for operational use cases.
CAP Theorem 📝

In distributed systems there's a theorem called CAP Theorem. It describes three characteristics and in theory only two are possible to achieve at the same time. This theorem exists because in a distributed network a series of machines work in unison to distribute and store data.
- Consistency - the data is the same across the cluster. You can access data from any node and get the same data.
- Availability - the cluster continues working and can respond to requests despite a node failing
- Partition Tolerance - the cluster continues working despite a communication break (partition) between two nodes.
For most distributed databases you will see a combination of two of these characteristics.
Introducing... Spanner 💬
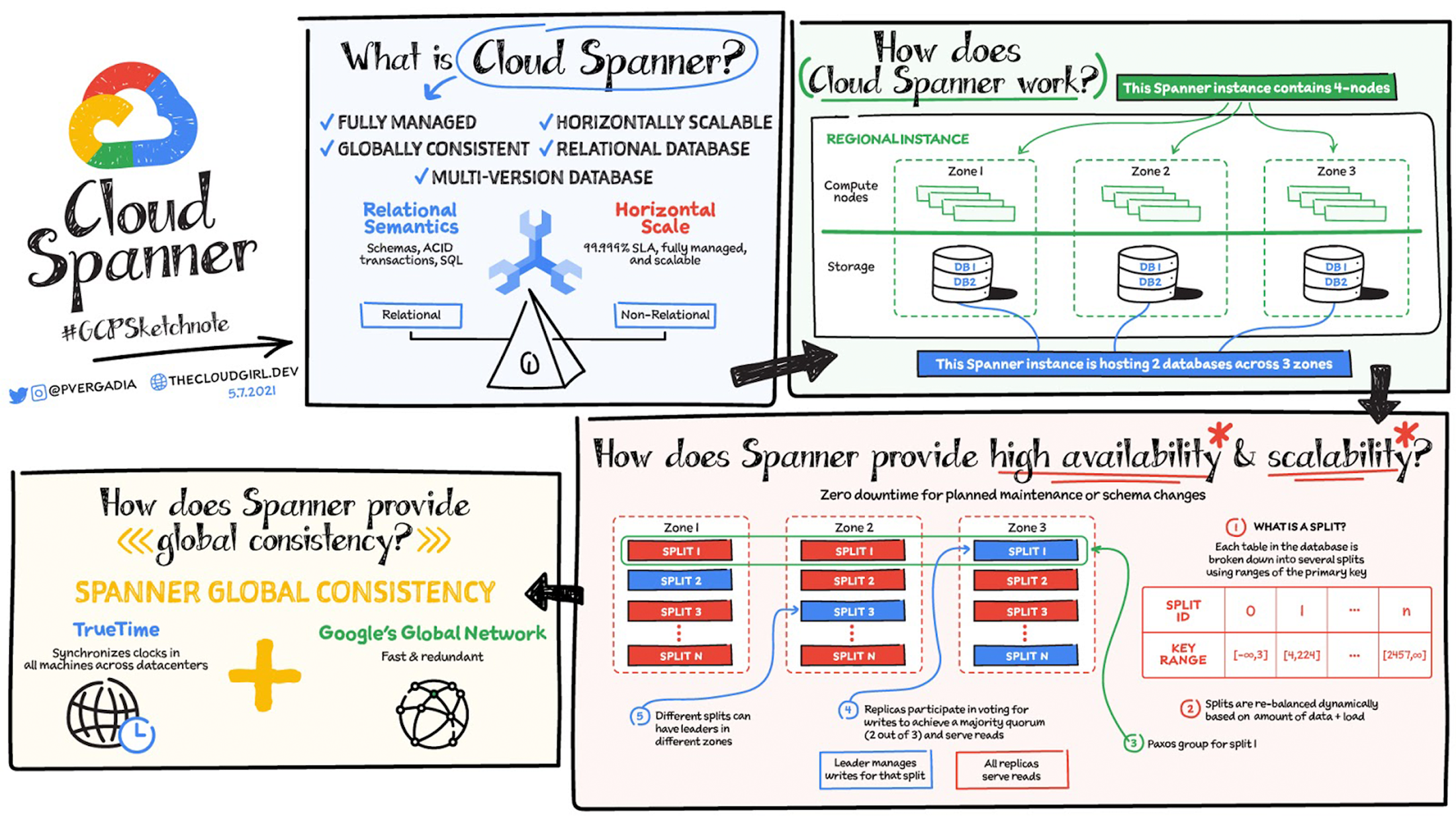 Taken from this Google Cloud blog post
Taken from this Google Cloud blog post
It seems that in order to use a relational database you miss out on horizontal scaling, but if you use NoSQL then you may not have ACID compliance.
Well, look no further, because on Google Cloud there's a database called Spanner. This is a fully managed, relational database that provides the benefits of a SQL database along with unlimited scale. It also offers up to 99.999% availability (less than 6 minutes downtime each year), provides automatic database sharding, and is accessible from the PostgreSQL ecosystem (it's not 100% PostgreSQL compatible, but dialects and psql support is available).
Overview of Benefits of using Spanner 💰
- Uses SQL
- Automatic Replication
- Offers Strong Consistency
- Offers High Availability
- Horizontally Scales
Architecture 🏛️
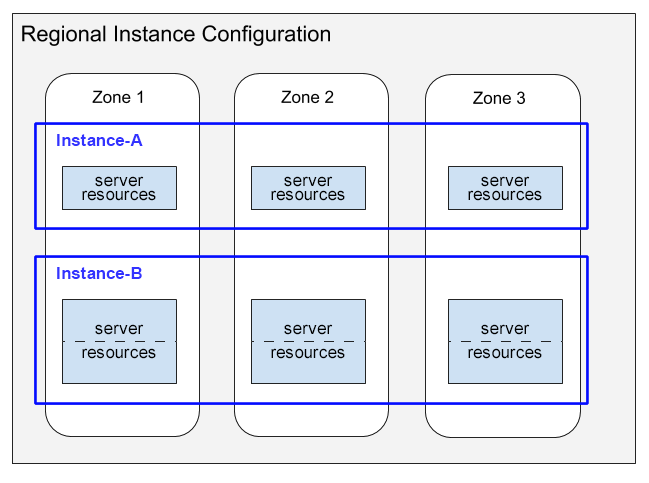
To use Spanner an instance must be created. This spins up compute nodes and resources for storing data in each zone, which depends on geographic region and amount of compute capacity for the instance. The instance will distribute resources across zones to ensure high performance and high availability.
The compute nodes gather and run queries to get results, which pulls data from the storage layer that uses Google's storage system, Colossus.
How Strong Consistency, HA, and Horizontal Scaling is achieved? 🤔
These explanations are kept at a high level. There are more steps for how they work, but for the purpose of this post, I want to explain the general mechanism without diving too deep into the details.
Horizontal Scaling and High Availability with Splits ➗
In Spanner, records are partitioned into Splits, and a row will be assigned to a split based on its primary key. Then splits are spread and replicated across nodes and zones. This is done dynamically by Spanner, and this enables the database to achieve up to 99.999% availability. However, you can run into performance issues if you don't design a primary key following best practices. For example, using sequential primary keys is an anti-pattern because the last split will get all new rows, thus creating a hotspot.
Finally, Spanner instances can easily be configured to add more/less compute.
For more on Spanner schema design best practices visit here
Strong Consistency TrueTime 💪
Spanner promises to provide External Consistency, the strictest concurrency control guarantee for transactions. This is achieved with TrueTime and Paxos.
TrueTime ⏳
Ensuring transactions are executed in order, without locking reads/writes, is challenging for distributed systems. If you have a banking system, you want a customer's deposits and withdrawals to happen precisely as intended.
TrueTime is a distributed clock that can generate monotonically increasing timestamps that ensures transactions are completed in order. Each timestamp created is guaranteed to be greater than the previous one. Also, Spanner uses multi-version concurrency control (MVCC) that stores multiple immutable versions of data. Whenever data is written, an immutable version of the data is created associated with the write timestamp. This can be used for read operations without blocking writes. Timestamps are critical in ensuring reads and writes are performed in order and without blocking operations.
Paxos 👑
Paxos is an algorithm for ensuring updates are made across splits to achieve strong consistency. It works by determining splits in scope for an update and elects one as a Leader, who is responsible for handling writes and ensuring other splits are updated in time. The leader asigns a timestamp, using TrueTime, them coordinates with the splits to update at that time and data is modified in the correct order.
When to use and things to look out for
Spanner is a great database, and there are certain scenarios when it's a good choice.
Good 👌
- If you are using a single machine relational database and need exceptional scale
- If you require high availability across multiple regions
- If you don't want to manage the infrastructure for your database
Things to be aware of ❗
- If you have an existing relational database then a lift and shift isn't possible. There are guides available on GCP's documentation for migrating from popular databases, like PostgreSQL to Spanner.
- If you have analytical workloads then a product like BigQuery might be better suited. Alternatively, if you need Spanner for supporting an application or service, but still want to analyse the data then you can use BigQuery's federated querying functionalityto read data directly.
- If you need very low latency then perhaps an in-memory database like Memorystory is better
Conclusion & Thank You 👋
This was an introductory post on GCP Spanner and covering elements of the architecture to explain why it's powerful. I might write a follow up post with sample code to show how you can get started with this service.
Thanks for reading, I hope you found it useful and I would love to read your comments.